
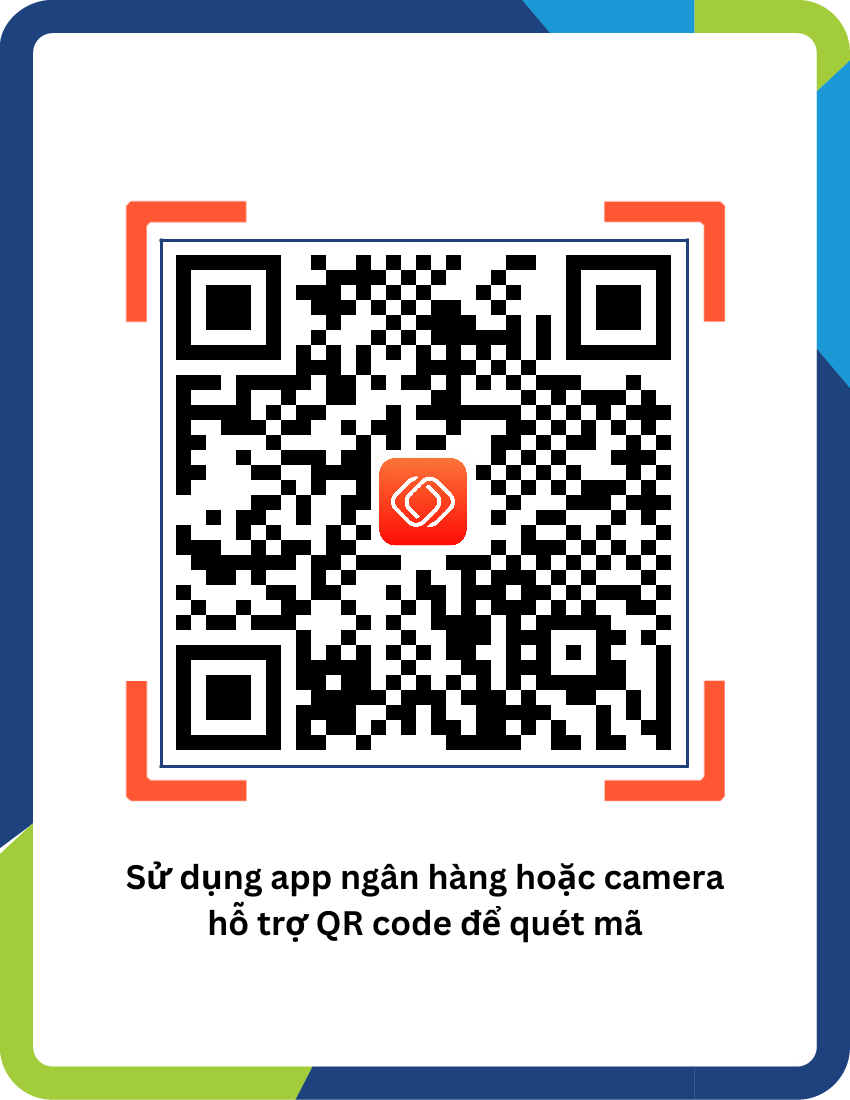
Nhà cung cấp
Ngân hàng thụ hưởng
Số tài khoản
Chủ tài khoản
Số tiền
Gửi hóa đơn + email vào page facebook sau: DEVOPSEDU.VN
*Mẹo: email bạn đăng nhập vào devopsedu.vn nên là email mà bạn sử dụng đăng ký series.
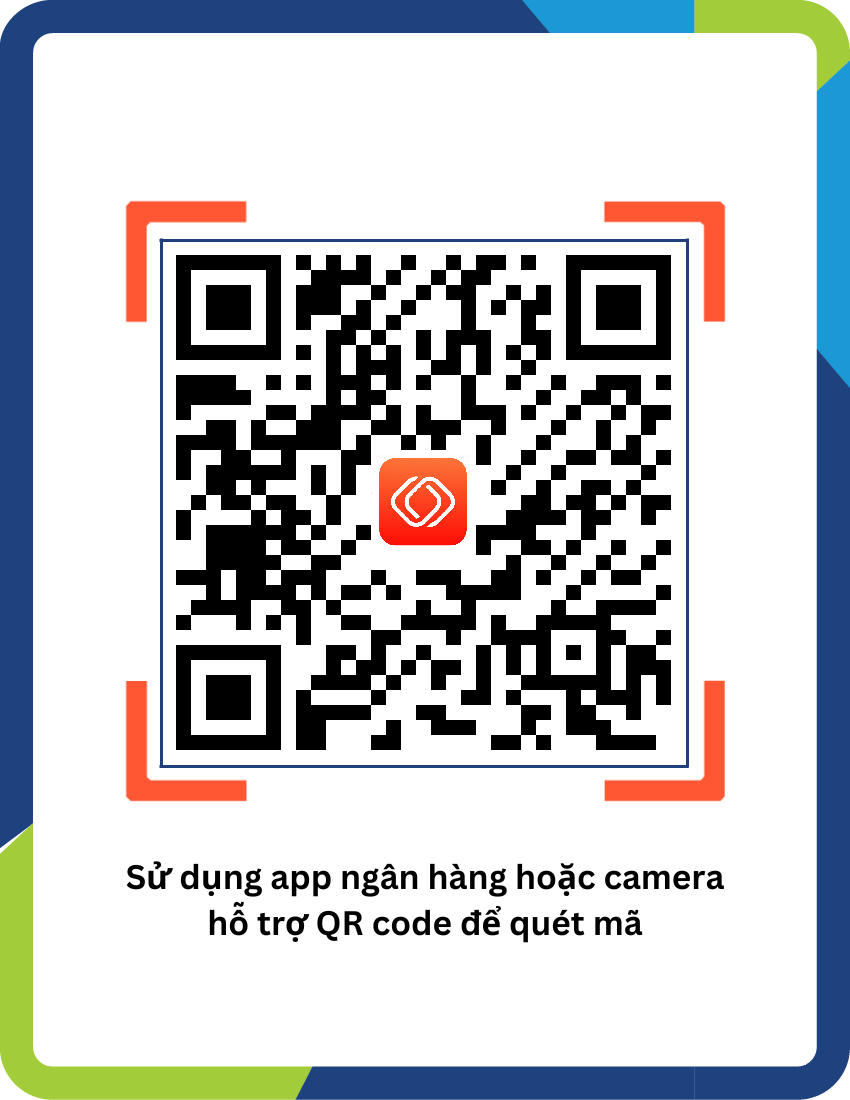
Nhà cung cấp
Ngân hàng thụ hưởng
Số tài khoản
Chủ tài khoản
Số tiền
Gửi hóa đơn + email vào page facebook sau: DEVOPSEDU.VN
*Mẹo: email bạn đăng nhập vào devopsedu.vn nên là email mà bạn sử dụng đăng ký series.
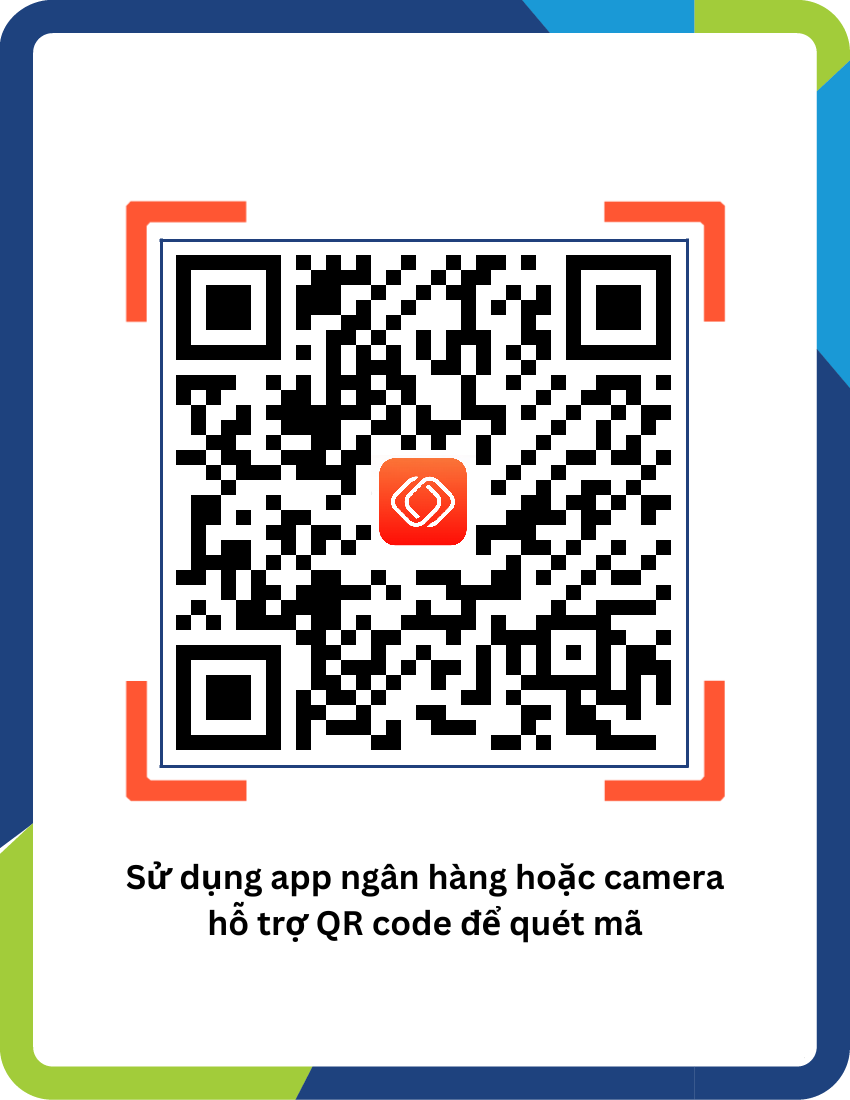
Nhà cung cấp
Ngân hàng thụ hưởng
Số tài khoản
Chủ tài khoản
Số tiền
Gửi hóa đơn + email vào page facebook sau: DEVOPSEDU.VN
*Mẹo: email bạn đăng nhập vào devopsedu.vn nên là email mà bạn sử dụng đăng ký series.
Nhà cung cấp
Ngân hàng thụ hưởng
Số tài khoản
Chủ tài khoản
Số tiền
Gửi hóa đơn + email vào page facebook sau: DEVOPSEDU.VN
*Mẹo: email bạn đăng nhập vào devopsedu.vn nên là email mà bạn sử dụng đăng ký series.
