1. Giới thiệu
Trong bất kỳ hệ thống giám sát nào, bảng giám sát và cảnh báo đều đóng vai trò quan trọng trong việc theo dõi và đảm bảo tính liên tục của hoạt động hệ thống. Dashboard giúp trực quan hóa các chỉ số và thông tin, trong khi Alert giúp phát hiện và xử lý sự cố kịp thời. Bài viết này sẽ hướng dẫn cách thiết kế hệ thống Dashboard hiệu quả, lên phương án triển khai hệ thống cảnh báo, cũng như tích hợp API để quản lý.2. Thiết kế hệ thống Dashboard
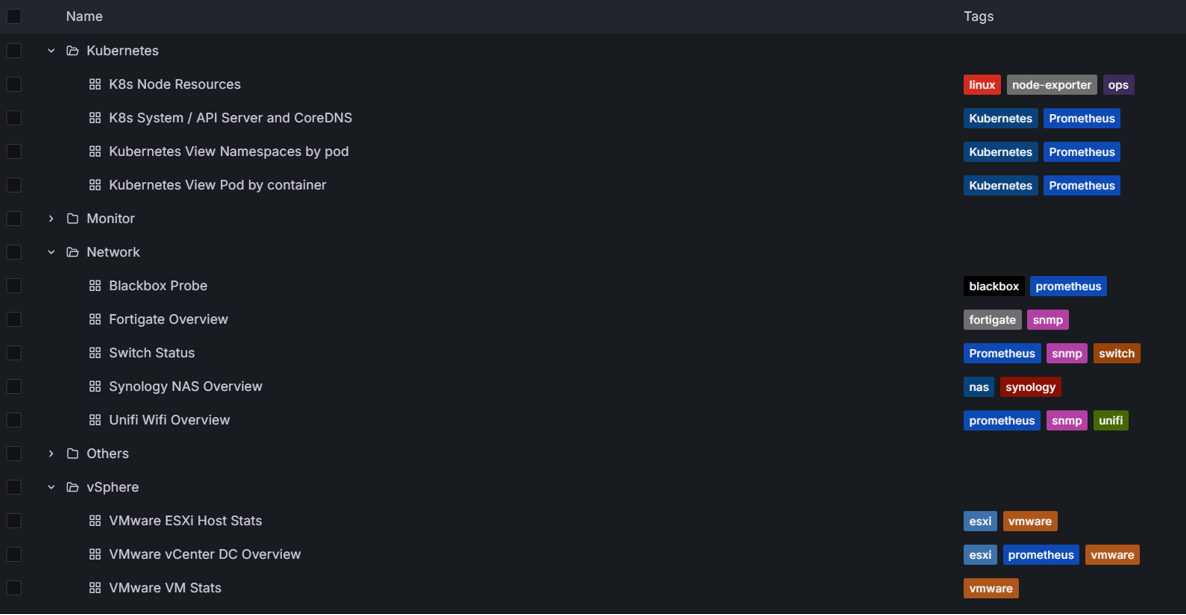
2.1. Lên ý tưởng và sắp xếp Dashboard hợp lý
Một Dashboard tốt cần phải cung cấp thông tin một cách rõ ràng, trực quan và dễ hiểu. Việc thiết kế cần phải cân nhắc đến các yếu tố sau:- Ưu tiên hiển thị hệ thống quan trọng: Dashboard cho các hệ thống máy chủ quan trọng nên được thiết kế chi tiết, bao gồm CPU, RAM, I/O, và băng thông mạng. Các dịch vụ quan trọng như Database, Web Server cũng cần được theo dõi kỹ lưỡng.
- Tối ưu hóa hiển thị trên một màn hình: Các biểu đồ quan trọng nhất nên được sắp xếp một cách cô đọng, dễ nhìn trên cùng một màn hình, giúp quản trị viên không phải cuộn trang liên tục.
- Phân chia theo nhóm chức năng: Nên chia các Dashboard thành nhiều nhóm, tập trung vào các lĩnh vực khác nhau của hệ thống, chẳng hạn như:
- Máy chủ và dịch vụ quan trọng
- Mạng và bảo mật
- Ứng dụng và dịch vụ endpoint
- Tài nguyên hệ thống
- Container ảo hóa (Docker/Kubernetes)
2.2. Thiết kế hệ thống Dashboard quan trọng
Dưới đây là một số gợi ý các thành phần chính trong một hệ thống Dashboard: Dashboard máy chủ và dịch vụ quan trọng: Tập trung vào những thành phần cốt lõi, giám sát trạng thái của các máy chủ quan trọng và tài nguyên của chúng. Các biểu đồ có thể bao gồm:- CPU/RAM sử dụng
- Dung lượng ổ đĩa
- Số lượng kết nối mạng
- Băng thông mạng tổng thể
- Số lượng gói tin vào/ra
- Tình trạng firewall
- Lượng yêu cầu HTTP/S
- Thời gian phản hồi của web server
- Lượng truy vấn vào cơ sở dữ liệu
 2.3. Một số cấu hình khởi tạo Grafana
Hôm trước chúng ta có file grafana.ini chứa cấu hình khởi tạo mặc định cho Grafana, hôm nay mình sẽ đưa ra một số cấu hình đáng chú ý trong đây:
Khối server: cấu hình giao thức, cổng, root_url sử dụng cho các tính năng short url và share dashboard.
2.3. Một số cấu hình khởi tạo Grafana
Hôm trước chúng ta có file grafana.ini chứa cấu hình khởi tạo mặc định cho Grafana, hôm nay mình sẽ đưa ra một số cấu hình đáng chú ý trong đây:
Khối server: cấu hình giao thức, cổng, root_url sử dụng cho các tính năng short url và share dashboard.
 Khối security: các options liên quan đến tài khoản, nhúng dashboard, cookie, csrf,…
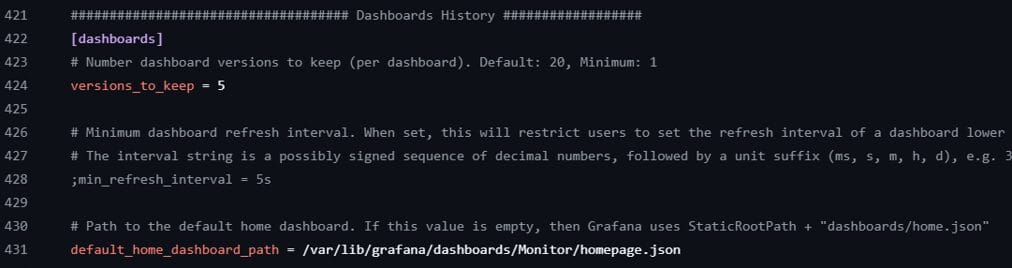
Khối dashboard: version history, cấu hình home dashboard
Ví dụ ở đây mình chỉ định đường dẫn tới file template Dashboard mặc định sẽ xuất hiện ở Home sau khi người dùng đăng nhập:
Khối security: các options liên quan đến tài khoản, nhúng dashboard, cookie, csrf,…
Khối dashboard: version history, cấu hình home dashboard
Ví dụ ở đây mình chỉ định đường dẫn tới file template Dashboard mặc định sẽ xuất hiện ở Home sau khi người dùng đăng nhập:
 Khối users: cấu hình liên quan user mặc định
Khối users: cấu hình liên quan user mặc định
 Ngoài ra có thể cấu hình path, database, cache, proxy,…
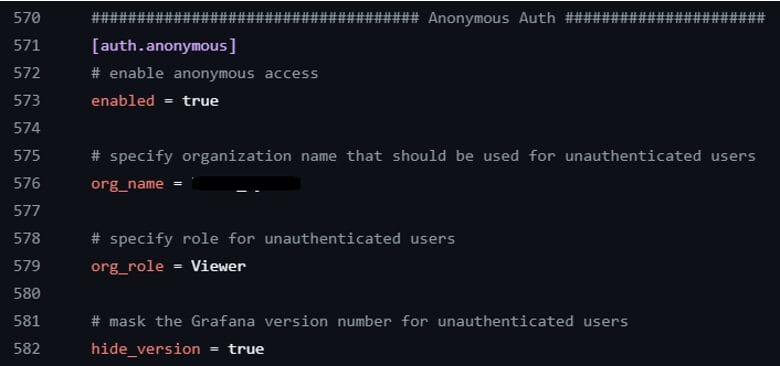
Ngoài ra Grafana còn có rất nhiều hình thức authenticate qua third party hoặc không cần đăng nhập (anonymous)
Ngoài ra có thể cấu hình path, database, cache, proxy,…
Ngoài ra Grafana còn có rất nhiều hình thức authenticate qua third party hoặc không cần đăng nhập (anonymous)
2.4. Phân Quyền Dashboard Theo Người Dùng
Grafana hỗ trợ khả năng phân quyền người dùng với 3 roles mặc định. Bạn có thể cấp quyền cho từng người dùng dựa trên nhu cầu và vai trò của họ:- Viewer: Chỉ xem được các Dashboard mà không thể chỉnh sửa.
- Editor: Có thể chỉnh sửa các Dashboard nhưng không thay đổi cấu hình hệ thống.
- Admin: Có toàn quyền quản lý và chỉnh sửa.

2.5. Tích Hợp API để quản trị Grafana
Grafana không cung cấp khả năng tạo user, group hoặc phân quyền từ khi khởi tạo và chỉ cho phép cấu hình qua HTTP API. (Bạn có thể bỏ qua bước này nếu không cần) Nếu muốn tự động triển khai từ config bạn có thể tạo một container chạy script gọi đến API của Grafana sau khi khởi tạo. Điều này giúp bạn triển khai các thay đổi trong hệ thống mà không cần truy cập thủ công vào giao diện Grafana. *Phần tùy vào sự sáng tạo mỗi người, mình chỉ Demo minh họa, không giải thích chi tiết Ví dụ tạo Team:
Ví dụ tạo Team:
# echo "Tạo team mới "IT"
# curl -sS -X POST -H "Content-Type: application/json" -u $GF_SECURITY_ADMIN_USER:$GF_SECURITY_ADMIN_PASSWORD -d '{
"name": "IT",
"email": "it@example.com"
}' http://grafana:3000/api/teams
Ví dụ tạo User:
# echo "Tạo mới user 'dev1'"
# curl -sS -X POST -H "Content-Type: application/json" -u $GF_SECURITY_ADMIN_USER:$GF_SECURITY_ADMIN_PASSWORD -d '{
"name": "dev1",
"email": "dev1@example.com",
"login": "dev1",
"password": "password",
"OrgId": 1
}' http://grafana:3000/api/admin/users
Ví dụ Thêm User vào Team:
# echo "Thêm user 'dev1' vào team "IT"
# curl -sS -X POST -H "Content-Type: application/json" -u $GF_SECURITY_ADMIN_USER:$GF_SECURITY_ADMIN_PASSWORD -d '{
"userId": '$DEV1_USER_ID'
}' http://grafana:3000/api/teams/$ TEAM_ID/members
Ví dụ Cập nhật quyền cho tất cả folder:
# echo "Lấy danh sách Folder uid"
# FOLDER_LISTS=$(curl -sS -H "Content-Type: application/json" -u $GF_SECURITY_ADMIN_USER:$GF_SECURITY_ADMIN_PASSWORD http://grafana:3000/api/folders | jq -r '.[].uid')
# echo "Cập nhật quyền View cho Team 'IT' với mọi folder"
for folder in $FOLDER_LISTS; do
echo "Update $folder..."
curl -sS -X POST -H "Content-Type: application/json" -u $GF_SECURITY_ADMIN_USER:$GF_SECURITY_ADMIN_PASSWORD -d '{
"items": [
{
"teamId": '"$TEAM_ID"',
"permission": 1
}
]
}' http://grafana:3000/api/folders/$folder/permissions
done
3. Thiết kế hệ thống Cảnh báo (Alerting)
3.1. Phương án triển khai hệ thống Cảnh báo
Để đảm bảo tính sẵn sàng cao (High Availability) của hệ thống Alert và khả năng cảnh báo kịp thời, có thể triển khai một Cluster Alert kết hợp nhiều server để đảm bảo khả năng chịu lỗi (Fault Tolerance). Hệ thống sẽ được thiết lập để gửi cảnh báo qua Telegram và email cho quản trị viên.3.2. Xác định các Quy tắc cảnh báo (Alerting Rules)
Alerting Rules là tập hợp các điều kiện xác định khi nào hệ thống cần gửi cảnh báo. Những quy tắc này nên được phân loại thành các mức độ ưu tiên khác nhau để tránh tình trạng quá tải cảnh báo không cần thiết:- Critical: Cảnh báo khi các thành phần cốt lõi của hệ thống như database hoặc web server gặp sự cố.
- Alert: Các vấn đề như lưu lượng mạng vượt quá mức dự kiến hoặc tài nguyên máy chủ gần cạn kiệt.
- Warning: Các cảnh báo liên quan đến hiệu suất giảm nhưng không gây gián đoạn lớn.
3.3. Cấu hình Cảnh báo trong Prometheus
Bạn có thể tạo nhiều rules, mỗi bộ rules vào một file riêng để dễ tìm kiếm và chỉnh sửa: Sau đó chỉ cần khai báo tất cả trong Prometheus thay vì từng file một:
Sau đó chỉ cần khai báo tất cả trong Prometheus thay vì từng file một:
 Bạn có thể lấy lệnh trong Expression để kiểm tra điều kiện trong Prometheus query.
Sau đây là ví dụ về một số Rules phổ biến mà mình sử dụng:
Mọi Rules đều được thêm các Labels là severity (tự định nghĩa) và annotations (ghi chú) để sử dụng cho tin nhắn cảnh báo. (Các bạn cũng có thể tùy chỉnh nội dung này)
Linux rules: (CPU, Memory, Disk)
Bạn có thể lấy lệnh trong Expression để kiểm tra điều kiện trong Prometheus query.
Sau đây là ví dụ về một số Rules phổ biến mà mình sử dụng:
Mọi Rules đều được thêm các Labels là severity (tự định nghĩa) và annotations (ghi chú) để sử dụng cho tin nhắn cảnh báo. (Các bạn cũng có thể tùy chỉnh nội dung này)
Linux rules: (CPU, Memory, Disk)
############# Define Rule Alert ###############
groups:
- name: Linux-alert
rules:
################ Linux High CPU Usage
- alert: Linux High CPU Usage
expr: 100 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by (instance) * 100 > 95
for: 5m
labels:
severity: warning
annotations:
summary: "Linux High CPU Usage ({{ $labels.instance }}) for 5m"
description: "CPU Usage is more than 95%n VALUE = {{ $value }}"
################ Linux High Memory Usage
- alert: Linux High Memory Usage
expr: (node_memory_Memtotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100 > 95
for: 5m
labels:
severity: warning
annotations:
summary: "Linux High Memory Usage ({{ $labels.instance }}) for 5m"
description: "Memory Usage is more than 95%n VALUE = {{ $value }}"
################ Linux Low Disk Space
- alert: Linux Low Disk Space
expr: 100 - (node_filesystem_avail_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100 > 95
for: 5m
labels:
severity: warning
annotations:
summary: "Linux Low Disk Space ({{ $labels.instance }})"
description: "Disk Space is used more than 95%n VALUE = {{ $value }}"
Windows Rules: (CPU, Memory, Disk)
############# Define Rule Alert ###############
groups:
- name: Windows-alert
rules:
################ Windows High CPU Usage
- alert: Windows High CPU Usage
expr: 100 - (avg by (instance, hostname) (irate(windows_cpu_time_total{mode="idle"}[1m])) * 100) > 95
for: 5m
labels:
severity: warning
annotations:
summary: "Windows High CPU Usage ({{ $labels.instance }}) for 5m"
description: "CPU Usage is more than 95%n VALUE = {{ $value }}"
################ Windows High Memory Usage
- alert: Windows High Memory Usage
expr: (windows_cs_physical_memory_bytes - windows_os_physical_memory_free_bytes) / windows_cs_physical_memory_bytes * 100 > 95
for: 5m
labels:
severity: warning
annotations:
summary: "Windows High Memory Usage ({{ $labels.instance }}) for 5m"
description: "Memory Usage is more than 95%n VALUE = {{ $value }}"
################ Windows Low Disk Space
- alert: Windows Low Disk Space
expr: 100 - (sum(windows_logical_disk_free_bytes{volume!~"Harddisk.*"}) by (instance, hostname)) / sum(windows_logical_disk_size_bytes{volume!~"Harddisk.*"}) by (instance, hostname) * 100 > 95
for: 5m
labels:
severity: warning
annotations:
summary: "Windows Low Disk Space ({{ $labels.instance }})"
description: "Disk Space is used more than 95%n VALUE = {{ $value }}"
Probe Rules: (HTTP, Error, Other)
############# Define Rule Alert ###############
groups:
- name: Probe-alert
rules:
################ Probe Request Failed
- alert: Probe Request Failed
expr: probe_http_status_code{job="blackbox-exporter-http"} == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe Request Failed ({{ $labels.instance }})"
description: "Host {{ $labels.hostname }} probe response error"
################ Probe HTTP Error
- alert: Probe HTTP Error Code
expr: probe_http_status_code{job="blackbox-exporter-http"} > 500
for: 1m
labels:
severity: error
annotations:
summary: "Probe HTTP Error Code ({{ $labels.instance }})"
description: "Host {{ $labels.hostname }} return code {{ $value }}"
################ Probe Check Failed
- alert: Probe Check Failed
expr: probe_success{job!="blackbox-exporter-http"} == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe Check Failed ({{ $labels.instance }})"
description: "Host {{ $labels.hostname }} is down!"
VMWare Rules: (Esxi, CPU, Memory, Datastore, VMs)
############# Define Rule Alert ###############
groups:
- name: VMWare-Host-alert
rules:
################ ESXi Disconnected
- alert: ESXi Disconnected
expr: vmware_host_connection_state == 0
for: 1m
labels:
severity: critical
annotations:
summary: "ESXi Disconnected ({{ $labels.host_name }})"
description: "Host {{ $labels.host_name }} unreachable!"
################ ESXi Host down
- alert: ESXi Host down
expr: vmware_host_power_state == 0
for: 1m
labels:
severity: error
annotations:
summary: "ESXi Host down ({{ $labels.host_name }})"
description: "Host {{ $labels.host_name }} has been down!"
################ ESXi High CPU Usage
- alert: ESXi High CPU Usage
expr: avg_over_time(vmware_host_cpu_usage[10m]) * 100 / avg_over_time(vmware_host_cpu_max[10m]) > 90
for: 1m
labels:
severity: warning
annotations:
summary: "ESXi High CPU Usage ({{ $labels.host_name }}) for 5m"
description: "CPU Usage is more than 95% over 5mn VALUE = {{ $value }}"
################ ESXi High Memory Usage
- alert: ESXi High Memory Usage
expr: avg_over_time(vmware_host_memory_usage[10m]) * 100 / avg_over_time(vmware_host_memory_max[10m]) > 95
for: 1m
labels:
severity: warning
annotations:
summary: "ESXi High Memory Usage ({{ $labels.host_name }}) for 5m"
description: "Memory Usage is more than 95% over 5mn VALUE = {{ $value }}"
################ Datastore Low Disk Space
- alert: Datastore Low Disk Space
expr: 100 - (vmware_datastore_freespace_size) * 100 / vmware_datastore_capacity_size > 95
for: 1m
labels:
severity: warning
annotations:
summary: "Datastore Low Disk Space ({{ $labels.ds_name }})"
description: "Datastore Space is used more than 95%n VALUE = {{ $value }}"
Rules cho VM trong vCenter:
- name: VMWare-VM-alert
rules:
################ VM High CPU Usage
- alert: VM High CPU Usage
expr: avg_over_time(vmware_vm_cpu_usagemhz_average[10m]) * 100 / avg_over_time(vmware_vm_max_cpu_usage[10m]) > 90
for: 1m
labels:
severity: warning
annotations:
summary: "VM High CPU Usage ({{ $labels.vm_name }}) for 10m"
description: "CPU Usage is more than 90% over 10mn VALUE = {{ $value }}"
################ VM High Memory Usage
- alert: VM High Memory Usage
expr: avg_over_time(vmware_vm_mem_usage_average[10m]) * 100 / avg_over_time(vmware_vm_memory_max[10m]) > 90
for: 1m
labels:
severity: warning
annotations:
summary: "VM High Memory Usage ({{ $labels.vm_name }}) for 10m"
description: "Memory Usage is more than 90% over 10mn VALUE = {{ $value }}"
################ VM Low Disk Space
- alert: VM Low Disk Space
expr: 100 - ((sum(vmware_vm_guest_disk_free) by (vm_name)/sum(vmware_vm_guest_disk_capacity) by (vm_name))) * 100 > 95
for: 1m
labels:
severity: warning
annotations:
summary: "VM Low Disk Space ({{ $labels.instance }})"
description: "Disk Space is used more than 95%n VALUE = {{ $value }}"
Lưu ý: Trên đây là ví dụ một số Rules phổ biến dựa trên tiêu chí của mình sử dụng, các bạn có thể tùy chỉnh dựa trên nhu cầu thực tế riêng.
3.4. Cú pháp Template Thông báo chi tiết
Alertmanager hỗ trợ template để tùy chỉnh nội dung cảnh báo theo mẫu chúng ta định nghĩa. Bạn có thể thêm các biến trong thông báo để cung cấp thông tin chi tiết về sự cố. Như bài cài đặt Alertmanager chúng ta đã khai báo nội dung Template trong file alertmanager.yml, hôm nay chúng ta sẽ tạo Template đó.
Bạn có thể sửa file template.tmpl như sau:
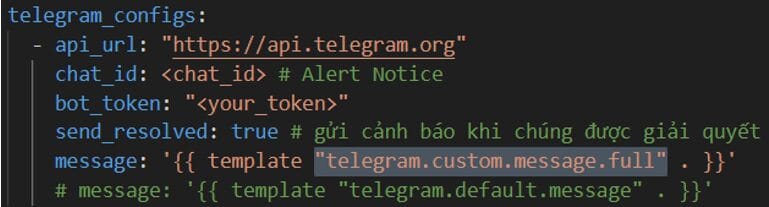 Ví dụ Template mặc định, dữ liệu cảnh báo chưa được xử lý:
Ví dụ Template mặc định, dữ liệu cảnh báo chưa được xử lý:
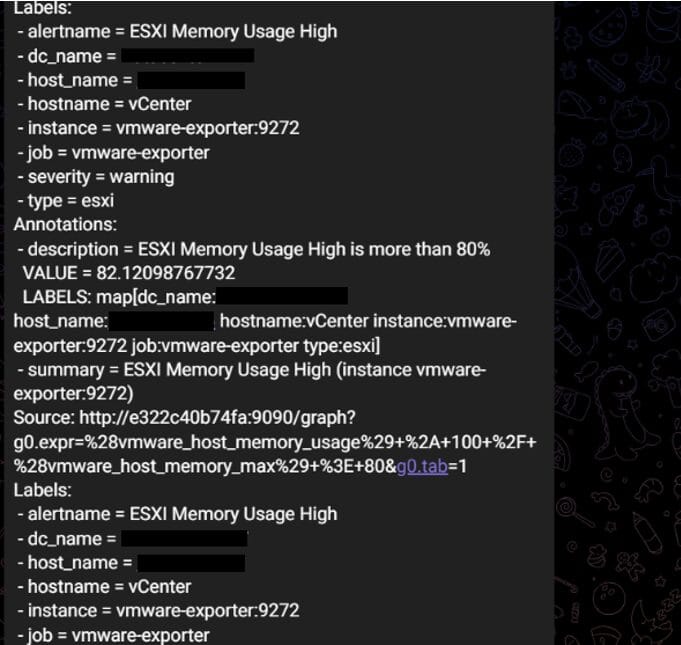 Đây là ví dụ tin nhắn đã được xử lý và định dạng từ dữ liệu thô của Prometheus:
Đây là ví dụ tin nhắn đã được xử lý và định dạng từ dữ liệu thô của Prometheus:
 Meo: Mục tiêu cô đọng tin nhắn chỉ trong một dòng đầu khi nhận thông báo từ điện thoại cũng có thể thấy tiêu đề và mức độ cảnh báo, ngoài ra là thời gian và chi tiết.
Ví dụ đây là mẫu Template tin nhắn mình sử dụng:
Meo: Mục tiêu cô đọng tin nhắn chỉ trong một dòng đầu khi nhận thông báo từ điện thoại cũng có thể thấy tiêu đề và mức độ cảnh báo, ngoài ra là thời gian và chi tiết.
Ví dụ đây là mẫu Template tin nhắn mình sử dụng:

 Bạn có thể tạo Dashboard dạng Alert list để lấy thông tin các cảnh báo hoặc sử dụng metrics ALERTS từ Prometheus
Bạn có thể tạo Dashboard dạng Alert list để lấy thông tin các cảnh báo hoặc sử dụng metrics ALERTS từ Prometheus
{{ define "__alert_content_message_full" }}{{ range . }}
🚩 [{{ .Labels.severity }}] {{ .Labels.alertname }} 🚩
📝 Sumary: {{ .Annotations.summary }}
📖 Description: {{ .Annotations.description }}
💣 Trigger time: {{ .StartsAt.Local.Format "15:04:05 MST 2006-01-02" }}
🏷 Labels:
{{ range .Labels.SortedPairs }}| {{ .Name }}: {{ .Value }} | {{ end }} {{ end }} {{ end }} {{ define "telegram.custom.message.full" }} {{ if gt (len .Alerts.Firing) 0 }} 🔥 {{ len .Alerts.Firing }} Alert(s) Firing: 🔥 {{ template "__alert_content_message_full" .Alerts.Firing }}{{ end }} {{ if gt (len .Alerts.Resolved) 0 }} ✅ {{ len .Alerts.Resolved }} Alert(s) Resolved: ✅ {{ template "__alert_content_message_full" .Alerts.Resolved }}{{ end }} {{ end }}
Một số biến có thể sử dụng:
- {{ .Labels.severity }}: Lấy nhãn severity.
- {{ .Labels.alertname }}: Lấy nhãn tên cảnh báo.
- {{ .Annotations.summary }}: Lấy ghi chú summary.
- {{ .Annotations.description }}: Mô tả chi tiết của cảnh báo.
- {{ .StartsAt.Local.Format “15:04:05 MST 2006-01-02” }}: Thời gian cục bộ và Format
- {{ range .Labels.SortedPairs }}: Lặp lại danh sách Labels và in ra
Ví dụ Template mặc định, dữ liệu cảnh báo chưa được xử lý:
Đây là ví dụ tin nhắn đã được xử lý và định dạng từ dữ liệu thô của Prometheus:
Meo: Mục tiêu cô đọng tin nhắn chỉ trong một dòng đầu khi nhận thông báo từ điện thoại cũng có thể thấy tiêu đề và mức độ cảnh báo, ngoài ra là thời gian và chi tiết.
Ví dụ đây là mẫu Template tin nhắn mình sử dụng:
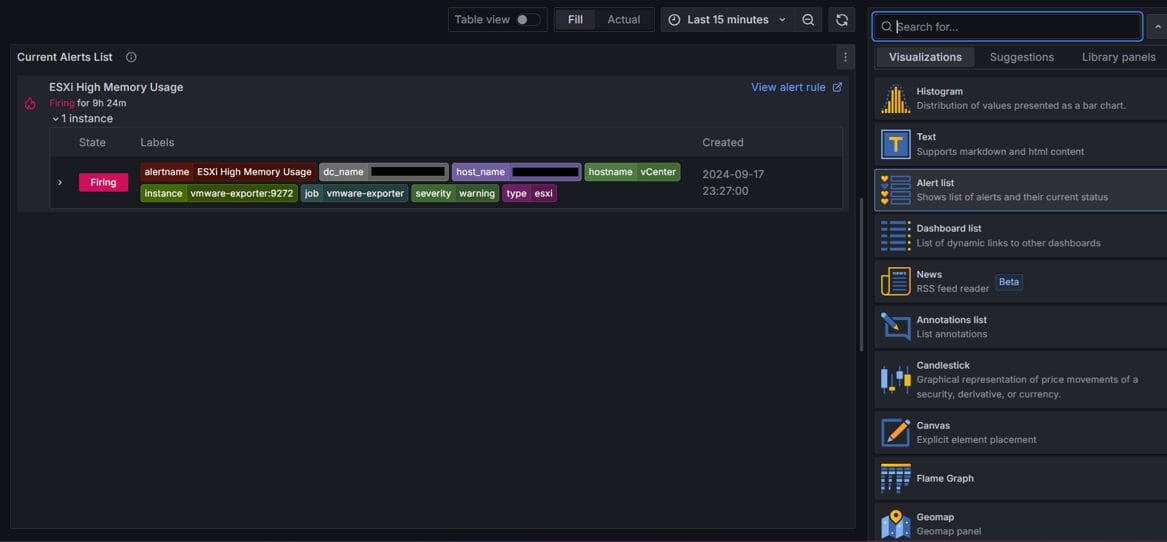
3.5. Xem thông tin Alert trong Grafana
Ngoài ra, vì đã tích hợp Alertmanager làm Data sources nên cũng có thể dễ dàng quản lý các cảnh báo trên Grafana:
Bạn có thể tạo Dashboard dạng Alert list để lấy thông tin các cảnh báo hoặc sử dụng metrics ALERTS từ Prometheus