1. Giới Thiệu
Trong bài viết này, chúng ta sẽ thực hành cấu hình một hệ thống giám sát toàn diện sử dụng Docker. Hệ thống này sẽ bao gồm các công cụ chính như Prometheus, Grafana, và nhiều Exporter khác nhau để thu thập dữ liệu từ các hệ thống như máy chủ, ứng dụng, và mạng. Bài viết sẽ hướng dẫn chi tiết cách cài đặt và cấu hình từng thành phần, từ Docker Compose file đến cách cấu hình các Exporter.2. Tổng quan về kiến trúc hệ thống giám sát (Cluster architecture)
Ở đây mình có một sơ đồ logic cách vận hành các thành phần giám sát trong hệ thống chúng ta sẽ triển khai như sau: *Đây là kiến trúc cơ bản của một site, nếu bạn muốn quản lý dữ liệu trên nhiều site có thể sử dụng Prometheus Fedaration hoặc tính năng Remote Read, Remote Write của Prometheus để lưu data về các External Storage (thanos, elasticsearch, greptimedb, influxdb, opentsdb,…)
*Đây là kiến trúc cơ bản của một site, nếu bạn muốn quản lý dữ liệu trên nhiều site có thể sử dụng Prometheus Fedaration hoặc tính năng Remote Read, Remote Write của Prometheus để lưu data về các External Storage (thanos, elasticsearch, greptimedb, influxdb, opentsdb,…)
3. Giải thích về luồng hoạt động của cụm (Cluster workflow):
Góc trên bên trái (Storage components)- Source code được pull/push từ Gitlab mỗi khi thay đổi (config được quản lý IaC nên không thể thay đổi từ GUI)
- Dữ liệu Monitor được lưu trữ và đồng bộ qua NFS Cluster giữa các Cluster đảm bảo HA
- Các config và source được quản lý và triển khai trên các Monitor Server Nodes
- Kiến trúc chính được chạy trên Docker Swarm để đảm bảo HA và Failover khi có sự cố
- Ở giữa là services chính Prometheus đóng vai trò trung tâm thu thập và tổng hợp metrics
- Có 3 services Blackbox Exporter, SNMP Exporter và VMware Exporter để thu thập metrics từ Endpoint
- Ngoài ra còn có Alertmanager dùng để đánh giá và tổng hợp cảnh báo dựa trên metrics
- Cuối cùng là Grafana giúp visualize dữ liệu thành biểu đồ cho Administrator theo dõi
- Bên ngoài container sẽ có các agent khác để thu thập metrics như Node Exporter, Windows Exporter, Kubernetes Exporter, Ceph Exporter, …
- Đây là 3 services chạy trong container nhưng expose ra bên ngoài để thu thập metrics về Prometheus
- Blackbox Exporter có nhiệm vụ thu thập “HTTP Probe” từ Web servers, “TCP Probe” từ SQL Servers, “ICMP Probe” từ Other Servers
- SNMP Exporter có nhiệm vụ thu thập metrics từ các thiết bị mạng như NAS, Fortigate, Pfsense, Unifi, Switch Core
- VMware Exporter có nhiệm vụ thu thập metrics từ vCenter như Esxi Hosts, Datastores, VMs resources
- Đây là các thành phần thuộc phạm vi quản lý của Alertmanager giúp cảnh báo khi có sự cố
- Các metrics thu thập được sẽ được đánh giá liên tục mỗi 15s qua bộ quy tắc Alert rules
- Khi khớp các điều kiện nhất định, cảnh báo sẽ được chia làm 3 mức độ nguyên trọng Severity
- Dựa trên mức độ nghiêm trọng, cảnh báo sẽ được điều hướng cho Bot gửi các luồng tương ứng
- Cuối cùng, Administrator sẽ nhận được cảnh báo từ nhóm Telegram khi có sự cố và được giải quyết
4. Cấu hình hệ thống giám sát từ Docker
Bài này chúng ta sẽ tập trung xây dựng các thành phần cốt lõi ở phần trung tâm trước. Chúng ta sẽ sử dụng Docker Compose/Stack để dễ dàng quản lý và triển khai các thành phần của hệ thống giám sát. Mình sẽ đưa cấu hình triển khai thực tế của mình nhưng đã lược bớt một số cấu hình phức tạp để đơn giản nhất có thể cho các bạn dễ hiểu. *Phần này yêu cầu các bạn có kiến thức cơ bản về Docker, những keyword cơ bản như đặt tên, image, network, volume mình sẽ không giải thích. Source Code mình sẽ để ở cuối bài viết! Sau đây là break down từng phần và giải thích:4.1. Khởi tạo các Thành phần chính
Tạo file docker-compose.yml hoặc docker-stack.yml (tùy kiến trúc bạn sử dụng), định nghĩa các thành phần chính như Prometheus, Grafana, Alertmanager.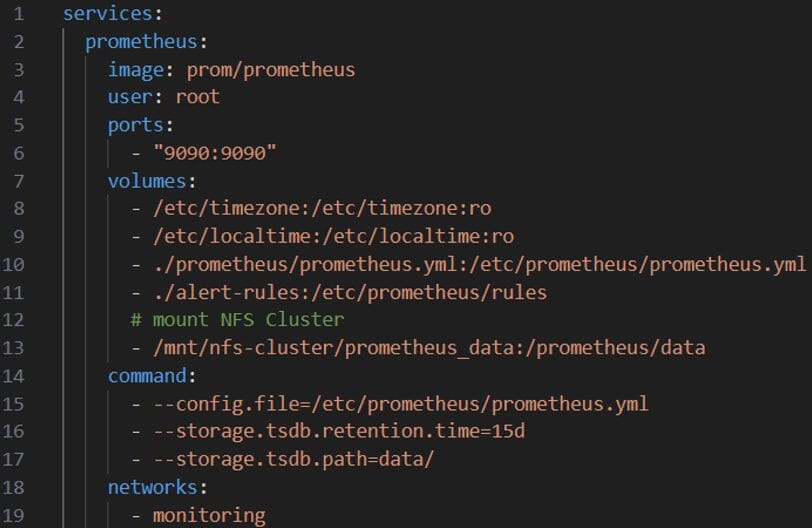 Giải thích:
Giải thích:
- Dòng 8,9: mount cấu hình giờ và timezone cho service
- Dòng 10: mount file cấu hình prometheus
- Dòng 11: mount folder alert rules (ở đây mình có nhiều rules)
- Dòng 13: mount folder prometheus data ra NFS (thay đổi với path nfs chính xác)
- Dòng 15: chạy prometheus với file cấu hình chỉ định
- Dòng 16: Đặt thời gian lưu TSDB là 15 ngày
- Dòng 17: đặt nơi prometheus lưu dữ liệu (sử dụng cho dòng 13)
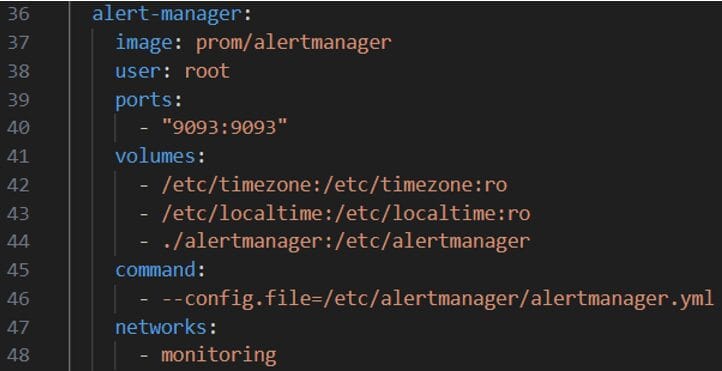 Giải thích:
Giải thích:
- Dòng 42,43: mount cấu hình giờ và timezone cho service
- Dòng 44: mount folder cấu hình alertmanager (nơi cấu hình template và alert routing)
- Dòng 46: chạy alertmanager với file cấu hình chỉ định
 Giải thích:
Giải thích:
- Dòng 142,143: mount cấu hình giờ và timezone cho service
- Dòng 144: mount cấu hình IaC provision datasources cho grafana
- Dòng 145: mount cấu hình IaC provision dashboards cho grafana
- Dòng 146: mount folder template dashboards
- Dòng 147: mount cấu hình init khi khởi tạo grafana
- Dòng 148: lấy enviroment từ file secret
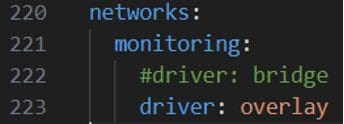 Các thành phần trong Kiến trúc giám sát sẽ giao tiếp với nhau thông qua mạng nội bộ được tạo ra bởi Docker (monitoring network).
Phần driver bạn sửa thành bridge (nếu sử dụng docker compose) hoặc overlay (nếu sử dụng docker stack).
Các thành phần trong Kiến trúc giám sát sẽ giao tiếp với nhau thông qua mạng nội bộ được tạo ra bởi Docker (monitoring network).
Phần driver bạn sửa thành bridge (nếu sử dụng docker compose) hoặc overlay (nếu sử dụng docker stack).
4.2. Cấu hình Prometheus
Các bạn tạo file prometheus.yml trong folder prometheus ngang cấp với file docker compose/stack vừa tạo. Sau đây là cấu hình minh họa và giải thích qua comment để tham khảo:
Sau đây là cấu hình minh họa và giải thích qua comment để tham khảo:
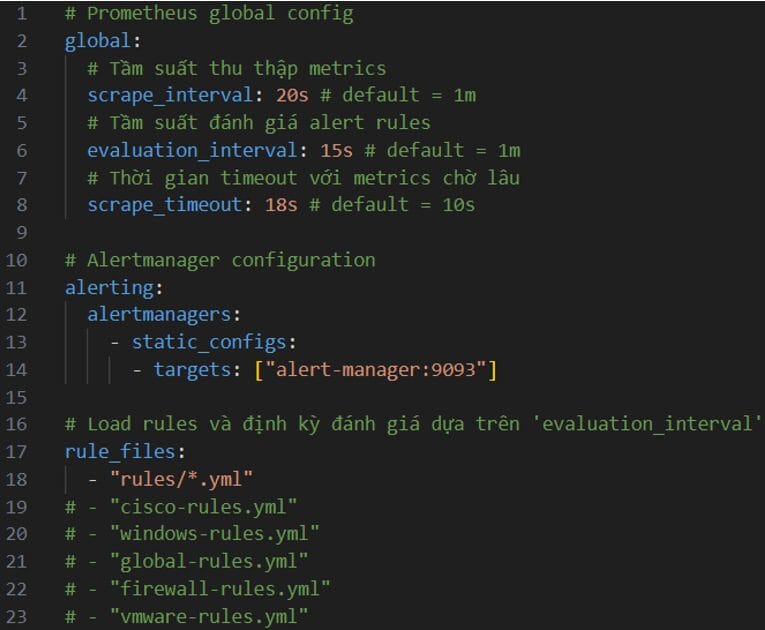 Sau đó cấu hình các target để prometheus scrape metrics từ đó, mỗi target có thể chỉ định thêm Label để sau này lọc đánh giá cho dễ.
VD ở đây mình thêm 3 Custom Label tự định nghĩa là hostname, type và zone
Sau đó cấu hình các target để prometheus scrape metrics từ đó, mỗi target có thể chỉ định thêm Label để sau này lọc đánh giá cho dễ.
VD ở đây mình thêm 3 Custom Label tự định nghĩa là hostname, type và zone
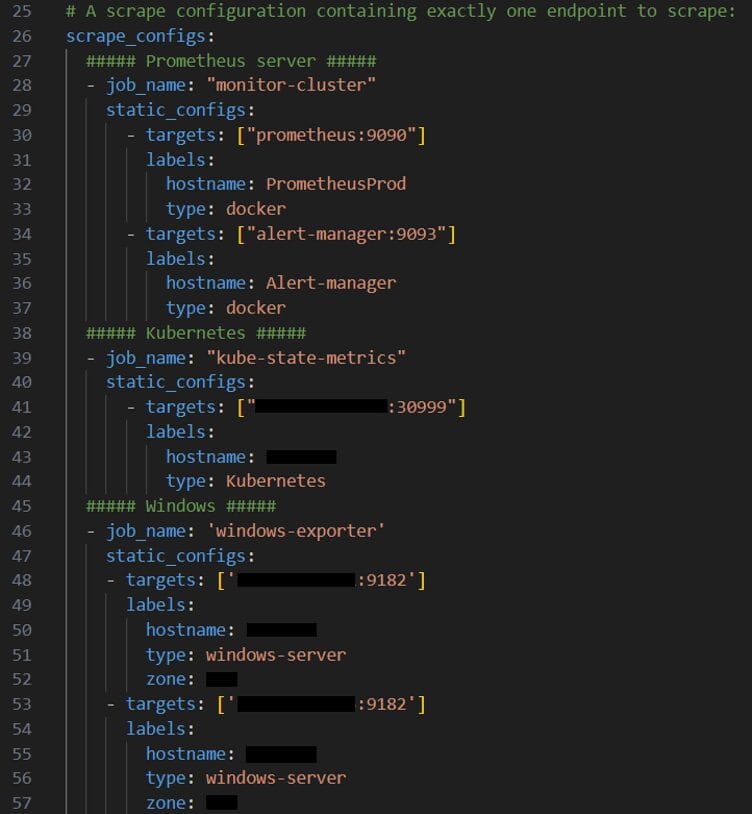 Để thêm các target thì chỉ cần thêm các block job_name tương ứng.
Để thêm các target thì chỉ cần thêm các block job_name tương ứng.
4.3. Cấu hình Alertmanager
Ở đây mình có file alertmanager.yml và template.tmpl thuộc folder alertmanager ngang hàng với file docker compose/stack: Sau đây là cấu hình minh họa và giải thích qua comment để tham khảo:
Sau đây là cấu hình minh họa và giải thích qua comment để tham khảo:
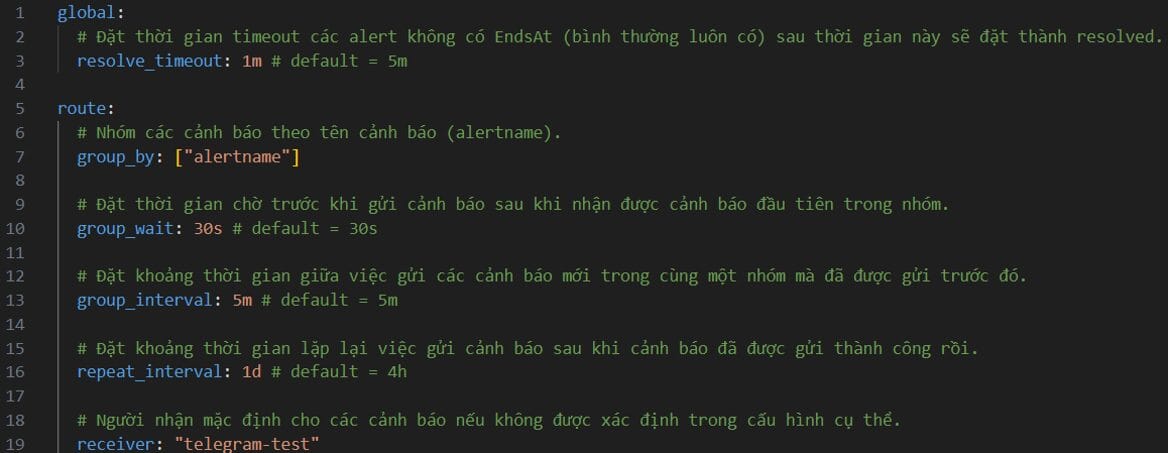 Ở đây giả sử mình có nhiều kênh liên lạc và cấu hình Alert Routing dựa trên độ nguy hiểm (severity) và đặt thời gian cảnh báo vào giờ làm việc.
*Nếu các bạn không có nhiều kênh nhận (telegram, email, webhook,…) thì có thể bỏ qua phần này.
Ở đây giả sử mình có nhiều kênh liên lạc và cấu hình Alert Routing dựa trên độ nguy hiểm (severity) và đặt thời gian cảnh báo vào giờ làm việc.
*Nếu các bạn không có nhiều kênh nhận (telegram, email, webhook,…) thì có thể bỏ qua phần này.
 Chỉ định cấu hình Template cảnh báo và cấu hình thời gian làm việc (nếu muốn chỉ cảnh báo vào giờ làm việc)
Chỉ định cấu hình Template cảnh báo và cấu hình thời gian làm việc (nếu muốn chỉ cảnh báo vào giờ làm việc)
 Dưới đây là ví dụ cấu hình các receiver dạng email, telegram và webhook:
Dưới đây là ví dụ cấu hình các receiver dạng email, telegram và webhook:
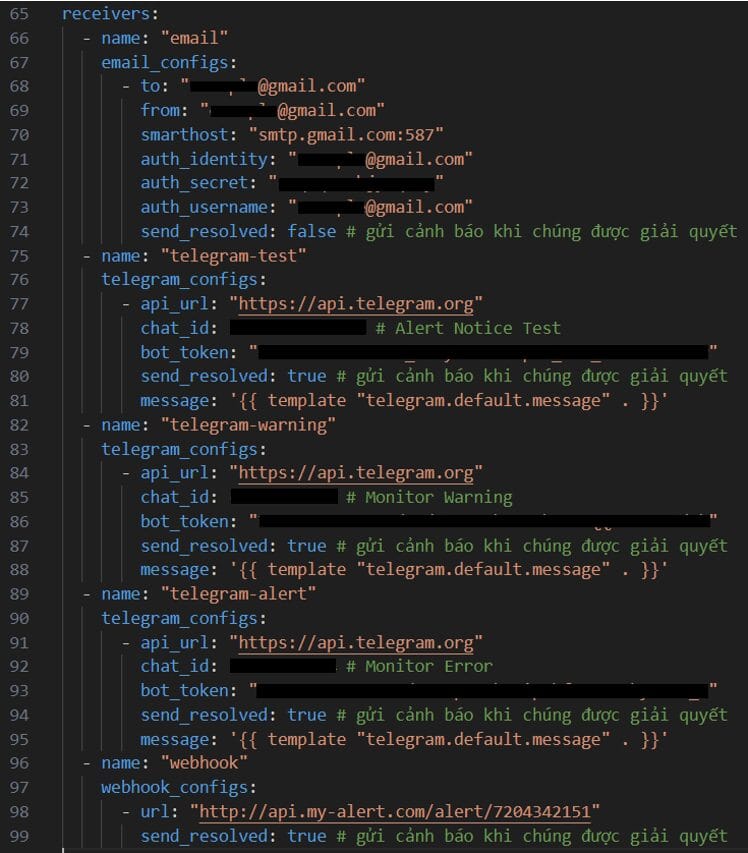 Telegram có một bộ template mặc định hoặc các bạn có thể tạo template riêng mình.
Các bạn có thể tham khảo các mẫu template email, slack, telegram ở đây:
https://github.com/prometheus/alertmanager/blob/main/template/default.tmpl
*Các bạn có thể search để biết cách tạo Telegram bot và lấy chat id và token
Cấu hình inhibit rule kiểm tra hai loại cảnh báo: cảnh báo mục tiêu (target) và cảnh báo nguồn (source). Cả hai cảnh báo này phải có các Label giống nhau dựa trên danh sách Label được xác định.
Telegram có một bộ template mặc định hoặc các bạn có thể tạo template riêng mình.
Các bạn có thể tham khảo các mẫu template email, slack, telegram ở đây:
https://github.com/prometheus/alertmanager/blob/main/template/default.tmpl
*Các bạn có thể search để biết cách tạo Telegram bot và lấy chat id và token
Cấu hình inhibit rule kiểm tra hai loại cảnh báo: cảnh báo mục tiêu (target) và cảnh báo nguồn (source). Cả hai cảnh báo này phải có các Label giống nhau dựa trên danh sách Label được xác định.

4.4. Cấu hình Grafana
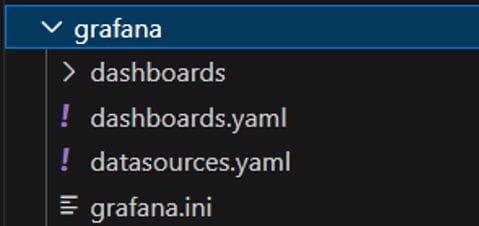
Cấu trúc thư mục grafana ngang hàng với file docker compose/stack như sau:- Folder dashboards chứa các file template Yaml dashboard (như hướng dẫn bài trước)
- File dashboards.yaml cấu hình provision để IaC Dashboard
- File datasources.yaml cấu hình provision để IaC Datasource
- File grafana.ini cấu hình mặc định khi khởi tạo (file này chạy container và lấy từ container, ban đầu chưa cần quan tâm)
 Cấu hình file dashboards.yaml:
Cấu hình file dashboards.yaml:
apiVersion: 1 providers: - name: DashboardProvider orgId: 1 folder: '' type: file disableDeletion: false updateIntervalSeconds: 10 allowUiUpdates: false options: path: /var/lib/grafana/dashboards foldersFromFilesStructure: trueCấu hình file datasources.yaml, các bạn có bao nhiêu datasource cung cấp tương ứng ở đây *Ở đây mình lấy cả datasource Alertmanager để visualize các thông tin về Alert luôn.
apiVersion: 1 datasources: - name: Prometheus type: prometheus url: http://prometheus:9090 access: proxy isDefault: true - name: Alertmanager type: alertmanager url: http://alert-manager:9093 access: proxy jsonData: implementation: prometheus handleGrafanaManagedAlerts: false
Trong mạng nội bộ Docker (monitoring network đã tạo), các node hiểu nhau qua hostname, đấy là lý do có thể sử dụng url như trên
File grafana.ini ban đầu các bạn không tạo, sau khi build xong sẽ được lấy từ container ra. Ban đầu về cơ bản các bạn chưa cần quan tâm file này.
 Tạo file .grafana.secret ngang hàng với file docker compose/stack chứa nội dung sau để cấu hình tài khoản admin mặc định khi khởi tạo grafana.
Tạo file .grafana.secret ngang hàng với file docker compose/stack chứa nội dung sau để cấu hình tài khoản admin mặc định khi khởi tạo grafana.

Tạo file .grafana.secret ngang hàng với file docker compose/stack chứa nội dung sau để cấu hình tài khoản admin mặc định khi khởi tạo grafana.
GF_SECURITY_ADMIN_USER=admin GF_SECURITY_ADMIN_PASSWORD=admin
4.5. Chạy thử và đảm bảo không có lỗi
Sau khi đã cấu hình đầy đủ các thành phần, các bạn chạy thử các thành phần trong kiến trúc và đảm bảo các thành phần hoạt động ổn định, không có lỗi xảy ra. Với Docker Compose (khởi tạo và kiểm tra):# docker compose up -d # docker compose ps -aVới Docker Stack (khởi tạo và kiểm tra):
# docker stack deploy -c docker-stack.yml Monitor # docker stack ps MonitorKiểm tra các dịch vụ:
- Prometheus: IP máy chủ và port 9090, đảm bảo tác target đang Up
- Alertmanager: IP máy chủ và port 9093
- Grafana: IP máy chủ và port 3000, đăng nhập tài khoản admin:admin
docker logs <container_name>