1. Giới thiệu
Trong kỷ nguyên phát triển của công nghệ container và lưu trữ phân tán,
Docker Swarm và
NFS Cluster là những thành phần không thể thiếu để xây dựng các hệ thống có khả năng mở rộng, chịu lỗi cao, và đảm bảo tính sẵn sàng.
Bài viết này sẽ khám phá kiến trúc của Docker Stack, NFS Cluster và cách chúng phối hợp để cung cấp giải pháp High Availability (HA) và Failover (FO), giúp hệ thống luôn hoạt động liên tục ngay cả khi gặp sự cố.
*Lưu ý: Tiền đề của bài viết này giả định bạn biết sử dụng “Docker cơ bản”, tôi chọn Docker vì nó phổ biến với đại đa số người sử dụng, ngoài ra bạn có thể làm tương tự với Kubernetes.
2. Docker Swarm: Tổng quan và Kiến trúc
2.1. Docker Swarm là gì?
Docker Swarm là một công cụ giúp quản lý và triển khai các container trên nhiều máy chủ, tạo thành một
cluster. Mục tiêu của Docker Swarm là cung cấp một giải pháp
orchestration hiệu quả, cho phép tự động phân bổ container, cân bằng tải và khả năng mở rộng dịch vụ.
- Service: Là một hoặc nhiều container chạy trên cùng một hình ảnh Docker. Service xác định cách container nên được triển khai và quản lý.
- Node: Là các máy chủ vật lý hoặc ảo chạy Docker Engine, mỗi node trong Swarm có thể là manager node (quản lý) hoặc worker node (thực thi container).
- Overlay Network: Mạng ảo kết nối các container trên nhiều node khác nhau. Overlay Network giúp các container có thể giao tiếp một cách bảo mật và ổn định.
- Volume: Một phần lưu trữ dữ liệu được gắn vào container để giữ lại dữ liệu khi container dừng hoặc bị xóa.
Docker Swarm sử dụng “
Stack” để định nghĩa các thành phần như service, volume, và network qua tệp YAML, giúp dễ dàng triển khai và quản lý các container trên nhiều node.
2.2. Docker Swarm và tính sẵn sàng (High Availability)
Docker Swarm được thiết kế để đảm bảo tính chịu lỗi cao nhờ vào khả năng
failover. Trong trường hợp một node bị lỗi, Docker Swarm sẽ tự động chuyển các container sang các node khác trong cluster để tiếp tục hoạt động.
Manager nodes cũng đóng vai trò quan trọng trong việc điều phối và sao lưu thông tin trạng thái của cluster, đảm bảo rằng nếu một manager gặp sự cố, các manager khác có thể tiếp quản ngay lập tức.
Ngoài ra, Swarm sử dụng mạng
Ingress Network giúp cân bằng tải (load balancing) traffic đến các Docker Node và expose traffic đều trên các Node dưới dạng dịch vụ. Các container trong Swarm được chạy dưới dạng Services (về mặt vật lý có thể chứa trong 1 Node bất kỳ nhưng về mặt logic sẽ được truy cập bởi bất kỳ Node nào). Đó cũng chính là lý do Services có thể nhân bản dựa trên khối lượng traffic.
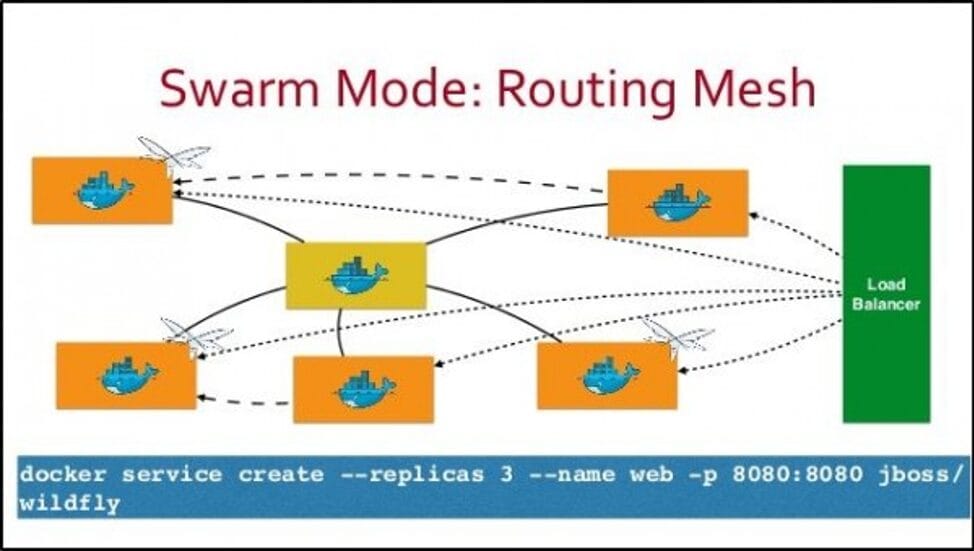 *Phần này chủ yếu giới thiệu về tính HA và FO của Swarm, các bạn có thể tự tìm hiểu thêm.
*Phần này chủ yếu giới thiệu về tính HA và FO của Swarm, các bạn có thể tự tìm hiểu thêm.
3. NFS Cluster: Kiến trúc và Chức năng
3.1. NFS Cluster là gì?
NFS (Network File System) là một giao thức cho phép các máy chủ chia sẻ tệp qua mạng, cho phép các hệ thống khác nhau truy cập cùng một hệ thống lưu trữ từ xa như thể đó là bộ nhớ cục bộ.
- NFS Server: Máy chủ chịu trách nhiệm quản lý và cung cấp các thư mục chia sẻ.
- NFS Client: Máy khách sử dụng NFS để kết nối và truy cập tài nguyên từ NFS Server.
- Mount Point: Vị trí trong hệ thống file của máy khách nơi các thư mục từ NFS Server được gắn kết.
NFS Cluster đảm bảo rằng dữ liệu luôn sẵn sàng và có thể truy cập từ nhiều máy chủ trong cùng một mạng lưới, giúp giảm thiểu rủi ro mất dữ liệu.
3.2. Sao lưu và Đồng bộ dữ liệu
Để đảm bảo tính toàn vẹn và khả năng truy cập liên tục, NFS Cluster có thể sử dụng các công nghệ sao lưu và đồng bộ dữ liệu như
GlusterFS hoặc
CephFS. Các dữ liệu trên NFS Server có thể được sao chép sang nhiều server khác trong cluster để phòng tránh rủi ro.
Trong trường hợp một server gặp sự cố, các server còn lại sẽ tiếp tục cung cấp dịch vụ mà không gián đoạn.
Ngoài ra có một số mô hình NFS Cluster khác như:
Pacemaker, Corosync, NFS hoặc
DRBD, Heartbeat, NFS.
3.3. High Availability và Failover trong NFS Cluster
Một trong những tính năng quan trọng của NFS Cluster là
High Availability. Khi NFS Cluster được cấu hình với nhiều NFS Server hoạt động ở chế độ dự phòng, nếu một server gặp sự cố, các server khác sẽ tự động tiếp quản và duy trì việc cung cấp dữ liệu. Điều này đảm bảo rằng hệ thống luôn sẵn sàng phục vụ, tránh tình trạng mất dữ liệu hoặc ngừng hoạt động.
4. Kết hợp Docker Swarm và NFS Cluster: Giải pháp toàn diện
4.1. Tích hợp Docker Swarm và NFS Cluster
Docker Swarm và NFS Cluster có thể được kết hợp để tạo ra một hệ thống có khả năng chịu lỗi và tính sẵn sàng cao. Docker Swarm quản lý container và đảm bảo tính linh hoạt khi phân phối dịch vụ, trong khi NFS Cluster đảm bảo rằng dữ liệu luôn có sẵn cho các container trên tất cả các node.
Khi một container cần lưu trữ hoặc truy cập dữ liệu, Docker sử dụng
volumes để gắn kết thư mục từ NFS Server vào container.
NFS volumes đảm bảo rằng dữ liệu có thể được chia sẻ và đồng bộ giữa các container, ngay cả khi chúng chạy trên các node khác nhau trong cluster.
4.2. Lợi ích của Docker Swarm và NFS Cluster
- High Availability: Cả Docker Swarm và NFS Cluster đều có khả năng failover, đảm bảo dịch vụ và dữ liệu không bị gián đoạn khi có sự cố.
- Scalability: Hệ thống có thể dễ dàng mở rộng khi cần thêm tài nguyên hoặc dịch vụ mới. Docker Swarm giúp mở rộng số lượng container, trong khi NFS Cluster giúp mở rộng khả năng lưu trữ dữ liệu.
- Data Consistency: NFS Cluster đảm bảo tính toàn vẹn và nhất quán của dữ liệu khi dữ liệu được chia sẻ giữa các node khác nhau.
- Efficient Resource Usage: Các container trong Docker Swarm có thể sử dụng cùng một nguồn dữ liệu từ NFS, giúp tối ưu hoá tài nguyên.
5. Hướng dẫn triển khai hệ thống Docker Swarm và NFS Cluster
5.1. Cài đặt Docker và Docker Compose:
Giả sử mình có 3 Nodes và muốn cả 3 đều tham gia làm Manager, thực tế có thể scale tùy nhu cầu:
- 192.168.24.101 (Manager)
- 192.168.24.102 (Manager)
- 192.168.24.103 (Manager)
Cài đặt Docker trên tất cả các Nodes
# curl -sSL https://get.docker.com/ | sudo sh
# sudo usermod -aG docker `whoami`
# sudo systemctl start docker.service
# sudo systemctl enable docker.service
5.2. Thiết lập Docker Swarm
Sau khi cài đặt Docker và Docker Compose, chúng ta tiến hành thiết lập Docker Swarm để quản lý môi trường Stack.
Trên máy Swarm Leader (Manager đầu tiên sẽ là Leader), chạy lệnh sau để tạo Docker Swarm cluster:
# docker swarm init --advertise-addr <ip manager>
Ví dụ:
# docker swarm init --advertise-addr 192.168.24.101

Với hai máy còn lại sẽ tham gia vào cluster với vai trò Manager node:
Các bạn chạy lệnh này để lấy lệnh join vào cụm cho Manager
# docker swarm join-token manager

Copy lệnh đó và chạy trên các Node còn lại (node02 và node03)
*Ví dụ này không sử dụng Worker node, bạn nên tách riêng Worker và Manager
Liệt kê các Docker Node đã tham gia vào trong Swarm:
# docker node ls

5.2. Triển khai NFS Cluster
Để đảm bảo tính HA và FO cho hệ thống lưu trữ, mình sẽ triển khai GlusterFS dùng để cấu hình Storage Cluster. Ở đây mình chọn GlusterFs bởi tính dễ sử dụng với mọi người, các bạn có thể hiểu nôm na nó vận hành giống tính chất của RAID.
Cài đặt GlusterFS trên các node:
# apt install -y glusterfs-server
# systemctl start glusterd
# systemctl enable glusterd
Đứng từ node1, tạo kết nối đến các node trong cluster:
# gluster peer probe node2
# gluster peer probe node3
*với node1, node2, node3 là IP của các Glusterfs Node

Kiểm tra trạng thái kết nối:
# gluster peer status

Tạo volume chia sẻ trên các node:
# mkdir /glusterfs
Tạo Replicated Volume (dữ liệu được sao chép đều trên mỗi brick, giống RAID 1):
Lệnh này các bạn chạy trên một node bất kỳ là được
# gluster volume create raid1 replica 3 transport tcp node1:/glusterfs node2:/glusterfs node3:/glusterfs force
*với node1, node2, node3 là IP của các Glusterfs Node

Khởi động volume và kiểm tra trạng thái:
# gluster volume start raid1
# gluster volume info

Cấu hình NFS trên GlusterFS sẽ sử dụng nfs-ganesha thay cho nfs-kernel-server:
# apt install -y nfs-ganesha-gluster
# vi /etc/ganesha/ganesha.conf

NFS_CORE_PARAM {
Protocols = 3,4;
}
EXPORT_DEFAULTS {
Access_Type = RW;
Squash = No_Root_Squash;
Disable_ACL = true;
}
EXPORT {
Export_Id = 101;
Path = "/glusterfs"; # mount path
FSAL {
Name = GLUSTER;
Hostname = "127.0.0.1";
Volume = "raid1"; # volume name
}
Access_Type = RW;
Squash = No_Root_Squash;
Sectype = "sys";
Clients = "192.168.24.0/24"; # share subnet
}
LOG {
# default log level
Default_Log_Level = WARN;
}
Sửa những phần mình comment tương ứng là được:
- Phần EXPORT, thay Path và Volume với tên volume vừa tạo
- Clients là dải mạng chia sẻ được phép kết nối
- Access là phân quyền Read+Write (RW)
Khởi động lại dịch vụ NFS-Ganesha:
# systemctl restart nfs-ganesha
# systemctl enable nfs-ganesha
Client kết nối tới NFS-ganesha (các máy Docker node):
Ở đây để đơn giản mình sửa dụng 3 node ở trên làm NFS Cluster và NFS Client luôn, với môi trường Product có thể tách riêng tùy mục đích sử dụng
# apt -y install glusterfs-client
# mkdir -p /mnt/nfs-cluster
# mount -t glusterfs 192.168.24.101:/raid1 /mnt/nfs-cluster
# echo '192.168.24.101:/raid1 /mnt/nfs-cluster glusterfs defaults,_netdev 0 0' | sudo tee -a /etc/fstab
# df -h
 *Các bạn cũng có thể tạo Virtual IP với Keepalived hoặc sử dụng IP một node bất kỳ
*Các bạn cũng có thể tạo Virtual IP với Keepalived hoặc sử dụng IP một node bất kỳ
6. Kết luận
Việc kết hợp Docker Swarm với NFS Cluster là một giải pháp toàn diện giúp đảm bảo tính sẵn sàng cao và khả năng chịu lỗi cho hệ thống. Docker Swarm giúp quản lý các container một cách linh hoạt, trong khi NFS Cluster đảm bảo rằng dữ liệu luôn sẵn sàng và an toàn. Đây là kiến trúc lý tưởng cho các hệ thống cần khả năng mở rộng và quản lý dữ liệu hiệu quả trong môi trường Production.