Bài 1: Bức tranh toàn cảnh về Monitoring System
Nội dung
Trong bối cảnh cơ sở hạ tầng CNTT ngày càng hiện đại, độ phức tạp của các hệ thống tiếp tục tăng lên. Nhiều công ty hiện vận hành các trung tâm dữ liệu lớn chứa nhiều máy ảo, máy chủ vật lý, thiết bị mạng và thiết bị bảo mật. Hệ thống này đóng vai trò then chốt trong hoạt động của công ty, cần đảm bảo mọi dịch vụ và ứng dụng hoạt động liên tục và ổn định. Đây là vấn đề mà mọi người điều hành doanh nghiệp luôn quan tâm.
1. Tầm quan trọng của việc xây dựng hệ thống giám sát hiện đại

Tất nhiên là không thể chờ hệ thống mỗi khi gặp sự cố và được báo thì mới biết, và cũng không thể hằng ngày truy cập vào tất cả hệ thống, dịch vụ để kiểm tra hết được, với hệ thống nhỏ thì không sao nhưng với hệ thống lớn thì rất phức tạp. Vì vậy, một hệ thống giám sát tự động, mạnh mẽ là điều rất cần thiết.
2. Tìm hiểu về các Monitoring System
Trong lĩnh vực giám sát chia làm một số “ranh giới”, mỗi lĩnh vực phục vụ một mục đích khác nhau:
- Security Monitoring (Giám sát bảo mật): Các hệ thống như SIEM (Quản lý sự kiện và thông tin), SOAR (Điều phối, tự động hóa và phản hồi) và SOC (Trung tâm điều hành bảo mật) tập trung vào việc giám sát các sự kiện và phản hồi bảo mật.
- Infrastructure Monitoring (Giám sát hạ tầng): Điều này bao gồm giám sát trạng thái của các thành phần cơ sở hạ tầng và tình trạng hệ thống như nhiệt độ máy chủ, trạng thái hệ thống, lưu lượng mạng, v.v.
- Application Monitoring (Giám sát ứng dụng): Các ứng dụng cần được thu thập thông tin Logs để đánh giá hiệu suất và cải thiện cũng như theo dõi trong quá trình ứng dụng vận hành.
Trong series này tôi chủ yếu sẽ trình bày về phần Infrastructure Monitoring (giám sát hạ tầng), hai phần còn lại tôi sẽ trình bày ở series tiếp theo.
3. Vậy giám sát hạ tầng gồm những gì?
Về việc tại sao cần giám sát thì rất rõ ràng rồi, nhưng để xây dựng được một hệ thống giám sát “hoàn chỉnh” thì còn rất nhiều vấn đề:
- Tính phức tạp và đa dạng: Sự đa dạng của các thành phần, từ máy chủ vật lý và máy ảo đến các thiết bị mạng và bảo mật, thêm cả các máy chủ chạy dịch vụ khiến việc giám sát tập trung trở nên khó khăn.
- Khối lượng dữ liệu: Với những hệ thống lớn và đa dạng thì khối lượng dữ liệu được thu về là rất lớn. Một hệ thống “hiệu quả” không chỉ là thu thập dữ liệu mà còn phải phân tích và xử lý một cách hợp lý.
- Độ tin cậy và hiệu suất: Hệ thống phải cung cấp thông tin và cảnh báo kịp thời. Ngoài ra phải đảm bảo tính sẵn sàng và chịu lỗi “cao hơn” hệ thống được giám sát. Điều gì sẽ xảy ra nếu hệ thống giám sát còn lỗi trước cả khi hệ thống thật bị lỗi.
4. Một số công cụ giám sát phổ biến
Hiện nay, đã có nhiều nghiên cứu và sản phẩm ra đời nhằm giải quyết bài toán này. Mỗi công cụ đều có điểm mạnh và hạn chế riêng, sau đây là một số công cụ giám sát all-in-one mà nhiều doanh nghiệp đang sử dụng:
- Nagios: Công cụ mã nguồn mở được sử dụng rộng rãi để giám sát các thiết bị, hệ thống và dịch vụ mạng. Tuy nhiên, việc cấu hình và mở rộng khá phức tạp.
- Zabbix: Cung cấp khả năng giám sát thời gian thực với các mô-đun dựng sẵn, nhưng có thể khó khăn với khả năng mở rộng trong môi trường rất lớn.
- PRTG: Phần mềm giám sát mạng chuyên nghiệp và linh hoạt, giúp phân tích và giám sát dựa trên các công cụ được tích hợp sẵn. Tuy nhiên chi phí mua bản quyền khá cao (1299$/y)
Ngoài ra còn có nhiều công cụ giám sát khác mà tôi cũng đã dùng như SolarWinds (1299$), Kafka, Graphite, Uptime Kume, Cacti, Icinga, CheckMk, Loki,…

5. So sánh các Monitoring Stacks
Ngoài các công cụ giám sát “ăn sẵn” như trên thì chúng ta có một số giải pháp “Stack” khác nhau, được thiết kế để đáp ứng các nhu cầu khác nhau:
- ELK Stack (Elasticsearch, Logstash, Kibana)
- EFK Stack (Elasticsearch, Fluentbit, Kibana)
- PNG Stack (Prometheus, Node Exporter, Grafana)
- TIG Stack (Telegraf, InfluxDB, Grafana)
- TICK Stack (Telegraf, InfluxDB, Chronograf, Kapacitor)
Mỗi “stack” này cung cấp một sự kết hợp độc đáo giữa các công cụ thu thập, lưu trữ và trực quan hóa dữ liệu, đáp ứng các loại nhu cầu giám sát khác nhau—từ số liệu hệ thống thời gian thực đến phân tích dữ liệu dài hạn.
6. Vậy làm thế nào để triển khai một hệ thống giám sát được coi là toàn diện
Đối với từng hệ thống cơ sở hạ tầng CNTT, chúng ta sẽ có hướng tiếp cận khác nhau:
- Giả sử một hệ thống nhỏ, ít thiết bị và độ phức tạp không nhiều thì có thể chọn giải pháp All-in-one như Zabbix.
- Với hệ thống lớn và nhân lực sẵn có thì có thể cân nhắc sử dụng các giải pháp All-in-one “free” mã nguồn mở như Nagios hoặc Zabbix. Nếu có tài chính thì có thể đề xuất sử dụng giải pháp enterprise như PRTG, SolarWinds.
- Các hệ thống All-in-one như trên đều tích hợp sẵn các module có sẵn và thu thập đầy đủ dữ liệu để phục vụ việc đó, dẫn đến việc dữ liệu thu thập lớn, khó có thể tinh chỉnh như Monitor Stack.
- Nếu bạn có kiến thức thì cũng có thể nghiên cứu các hệ thống “Monitoring Stack” cho phép Customize sâu hơn cũng như đảm bảo tính “phân tán”.
Và rất nhiều use-case khác nhưng chủ yếu có một số hướng đi như vậy, bạn nào cần tư vấn thì có thể liên hệ tôi sẽ hỗ trợ chi tiết hơn. Trong series này tôi sẽ nói về PNG Stack, một Monitoring Stack được đa số công ty tại Việt Nam sử dụng nhiều nhất hiện nay.
6.1. Lên phương án triển khai hệ thống
Vì series này liên quan đến vấn đề thực tế cũng như là xây dựng một hệ thống lớn nên không thể mất ngày một ngày hai là xong được mà cần phải có quy trình. Sơ qua thì công việc trong series này của chúng ta sẽ như sau:
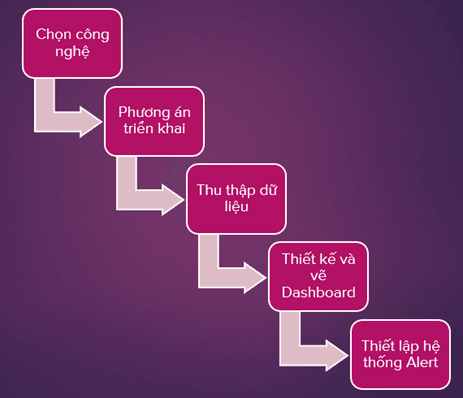
6.2. Triển khai và quản lý các thành phần
Về cơ bản kiến trúc cốt lõi của PNG Stack sẽ như sau:
- Prometheus thành phần chính giúp thu thập và lưu trữ dữ liệu giám sát.
- Grafana giao diện hiển thị giúp visualize dữ liệu, tạo dashboard để dễ dàng theo dõi.
- Alertmanager trình xử lý luồng thông tin và cảnh báo, điều hướng hành động khi có sự cố.
- Các Exporters giúp thu thập dữ liệu (hiểu đơn giản là các agent) như Node Exporter cho Linux servers, Windows Exporter cho Windows servers, SNMP Exporter cho thiết bị mạng, Blackbox Exporter cho probe check, VMWare Exporter cho vSphere.
Để đảm bảo tính phân tán, kiến trúc sẽ được tích hợp với Docker Swarm hoặc Kubernetes để quản lý container có thể mở rộng và Loadbalancing qua Ingress Network.
Triển khai các giải pháp long-term storage như Elasticsearch/GreptimeDB/Thanos hoặc liên kết Fedaration Prometheus-Prometheus để lưu giữ dữ liệu lịch sử để phân tích.
6.3. Tự động hóa với IaC
Sau đó các bạn có thể tự động triển khai và cập nhật bằng IaC sử dụng các công cụ như Ansible, Terraform hoặc GitLab CI/CD.
Mục tiêu là sẽ đưa hết tất cả cấu hình về mức nguyên thủy nhất của IaC đó là Provisioning. Trong Series này, mọi cấu hình sẽ được build từ Docker, giúp mỗi lần build hệ thống sẽ là build mới và giống hệt nhau về kết quả.
Lưu ý: Các bạn có kinh nghiệm có thể triển khai với Kubernetes theo cách tương tự, ở đây mình muốn giới thiệu hướng tiếp cận đơn giản nhất cho hầu hết mọi người đều có thể làm được.
6.4. Đảm bảo cảnh báo hiệu quả
Sau cùng chúng ta sẽ cấu hình Alertmanager để tích hợp với các công cụ thông báo như Telegram/Slack/Email để giúp cảnh báo sớm nhất cho quản trị viên theo thời gian thực.
Đồng thời tùy chỉnh ngưỡng cảnh báo để giảm tiếng ồn và định tuyến cảnh báo theo đường đi nó cần đến (Alert Routing).
7. Kết luận
Trong môi trường CNTT ngày nay, việc xây dựng một hệ thống giám sát toàn diện, hiện đại không chỉ là điều cần thiết mà còn là một lợi thế chiến lược. Nó đảm bảo rằng các hệ thống vẫn hoạt động, hiệu suất được tối ưu và các vấn đề tiềm ẩn được xác định và giải quyết trước khi chúng leo thang.
Với các công cụ như Prometheus, Grafana và triển khai tự động thông qua IaC, các công ty có thể xây dựng một hệ thống giám sát mạnh mẽ, đáp ứng nhu cầu của cơ sở hạ tầng phức tạp, quy mô lớn. Đầu tư vào một hệ thống giám sát có kiến trúc tốt không chỉ bảo vệ hoạt động CNTT của công ty mà còn cung cấp nền tảng cho sự phát triển và khả năng mở rộng trong tương lai.


Quá hay anh ơi!
Bài viết hay quá. Mong sớm có serie về Security Monitoring ạ
Rất dễ hiểu và hay ạ
Cảm ơn anh.